







Woolworths Upgrades Olive Chatbot to AI Shopping Agent with Google Gemini
Woolworths has announced a significant upgrade to its Olive customer service chatbot, leveraging Google Cloud’s Gemini Enterprise platform to transition the tool into a personalized shopping assistant. The updated Olive will feature "agentic" capabilities, allowing it to perform multi-step tasks such as meal planning and building grocery baskets based on voice inputs or handwritten recipe photos. This report examines the operational changes, data privacy considerations, and commercial neutrality policies governing the new system, as well as how this move aligns with global trends in conversational commerce.

Australia Challenges X Over Grok AI Safety and Deepfake Concerns
Australia’s eSafety Commissioner has contacted X following a sharp rise in reports regarding the misuse of its generative AI tool, Grok. The regulator cited concerns over the creation of non-consensual explicit imagery and potential risks to children. This inquiry aligns with similar regulatory investigations in the UK and Asia, and precedes the commencement of new Australian online safety codes scheduled for March 2026.
What Is Chatly AI? Features, Models and Security Risks Explained
ChatlyAI.app is a conversational AI platform developed by Vyro AI that aggregates multiple large language models, including GPT, Claude, and Gemini, into a single interface. This report outlines the app’s core features, document analysis capabilities, and data handling policies. It also details the security context following the 2025 breach report regarding unsecured logs and compares Chatly’s governance to platforms like ChatGPT and Perplexity.

Grok AI Faces Global Regulatory Backlash Over Image Safety
Regulators across Europe and Asia have launched inquiries into X’s Grok AI following reports that its image editing tool was used to generate non-consensual explicit imagery. As complaints surge regarding the safety of the new feature, authorities in the EU, UK, India, and other jurisdictions are demanding immediate safety updates and compliance with digital safety laws to protect users from deepfake abuse.

PYXA.AI Review 2026: Is the $49.99 Lifetime Deal Sustainable?
PYXA.AI promotes a consolidated AI dashboard for a single lifetime payment, aiming to disrupt the subscription model. This analysis examines the viability of this offer, detailing how the company's "Fair Use" policies, reliance on third-party models, and usage-based refund strictures affect long-term user access and service sustainability.
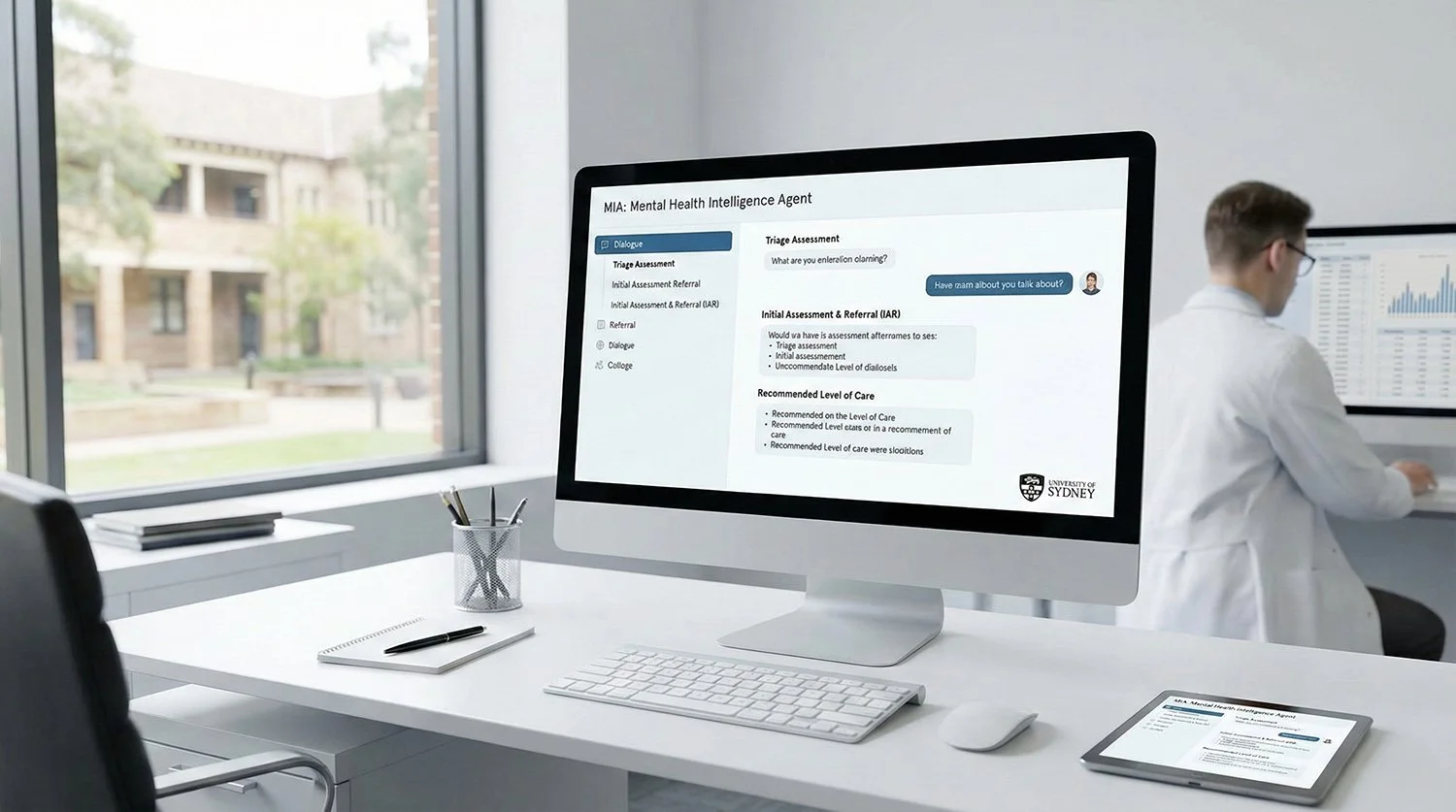
MIA: The New AI Chatbot Built for Safe Mental Health Triage
ABC News reports on the development of MIA, a mental health chatbot from the University of Sydney designed to triage users using clinical frameworks rather than general conversation. Unlike general-purpose AI, MIA relies on a closed knowledge bank to minimize errors and aligns with Australian government referral standards (IAR). The system is currently in testing with a public release expected in 2026.

myGov Contact Page: Digital Assistant Prioritized for 24/7 Support
The myGov contact page currently advises users to utilize the Digital Assistant as a primary step for support. As of 23 December 2025, the page explicitly positions the tool as an "any time" option for answering common questions about accounts and linked services. This guidance appears alongside standard helpdesk details, reinforcing a self-service approach for routine inquiries without relying on generative AI.

Grok’s Australian Data Mystery: High Traffic Rank vs. Missing Market Share
Public data on Grok’s usage in Australia appears contradictory. This report analyzes why Similarweb ranks the AI chatbot highly while StatCounter excludes it entirely, clarifying the technical distinction between web traffic rankings and referral header data.

Beesoft Launches AI-Powered EV Evolution Platform for Australian Market
Beesoft Solutions has launched EV Evolution, an information platform centered around a custom-trained AI chatbot tailored for the Australian electric vehicle landscape. The platform provides users with information on EV availability, charging infrastructure, and regional government incentives. It aims to reduce the complexity of researching electric vehicle ownership by consolidating data into a conversational interface.

Google Rolls Out Gemini 3 Flash as Its New Fast Default Across Search AI Mode and The Gemini App
On December 17, 2025, Google released Gemini 3 Flash, a new multimodal model designed to replace Gemini 2.5 Flash as the default engine for Google Search AI Mode and the Gemini app. Prioritizing low latency and cost-efficiency, the model is now available across consumer, developer, and enterprise platforms.

Google Blurs The Line Between Gemini Chat and NotebookLM Research Notebooks
Google has implemented new integrations allowing NotebookLM notebooks to be used directly within Gemini interfaces. This report details the functionality for consumer and enterprise users, including the ability to attach notebooks as prompt inputs and the specific governance controls retained by administrators.

NotebookLM vs Gemini 3 Pro for Research: What Is Actually Different?
Google now offers two distinct workflows for research: the source-grounded NotebookLM and the reasoning-focused Gemini 3 Pro. This analysis breaks down the November 2025 updates, including Deep Research and the new "Thinking" mode, to help users understand the practical differences in verification, data privacy, and use cases.

ChatGPT Holds 79.9% of Australia’s Chatbot Market in Nov 2025
Statcounter’s November 2025 data places ChatGPT as the clear leader in Australian chatbot referrals. This market snapshot frames a week of competitive releases, including Google’s Gemini 2.5 Flash Audio and Microsoft’s integration of GPT-5.2 into Copilot, as providers vie for user attention through browser and voice features.

OpenAI Launches GPT-5.2: First Model to Hit 100% on AIME Math
OpenAI has launched GPT-5.2, marking a historic milestone as the first model to achieve a verified 100% score on the AIME 2025 math benchmark without external tools. Released on December 11 amid intensifying competition with Google's Gemini 3, the update introduces "Thinking" capabilities and a massive 400,000 token context window.

Australia Enforces Under-16 Social Media Ban as 25% of Teens Use AI Chatbots
Australia’s new laws banning social media for under 16s have come into force, placing the burden on major platforms to enforce age limits or face significant civil penalties. As access to mainstream apps tightens, safety commissioners and researchers warn of a potential migration to AI companion tools, which are currently less regulated and increasingly used by vulnerable youth for advice and support.

Google NotebookLM Mobile Adds Camera Input & 1M Token Context Support
Google’s December update for NotebookLM mobile introduces direct camera capture, allowing users to add photos as sources for grounded AI analysis. While the app now leverages a 1 million token context window to process these images, Mind Map generation remains limited to the web experience.

AI Adoption Hits 54.6% as Gemini Challenges ChatGPT’s Dominance
New 2025 data indicates generative AI has reached mainstream status with 54.6% adoption among U.S. adults. As ChatGPT’s growth stabilizes, competitors like Google Gemini and Microsoft Copilot are expanding the market into a diverse ecosystem of specialized assistants, shifting the dynamic from a single-leader story to a multi-platform race.

Microsoft Cuts Copilot Price to US$21 as Users Top 150 Million
Microsoft is lowering the entry cost for its AI assistant with a new US$21 business tier and introducing Agent 365 to oversee autonomous workflows. Despite reporting 150 million monthly users, the tech giant faces ongoing scrutiny from IT leaders regarding integration complexity and return on investment, prompting a strategic shift toward multi-model support with Anthropic and enhanced enterprise governance controls.

Anthropic Launches Claude Opus 4.5: 80.9% Coding Score & New USD 5 Pricing
Anthropic has released Claude Opus 4.5, a new frontier model engineered for complex coding and agentic workflows. Achieving a record 80.9% on the SWE-Bench Verified benchmark, the system outperforms key rivals while introducing variable "Effort" settings that can reduce token consumption by up to 76%. With API pricing lowered to US$5 per million input tokens, Opus 4.5 targets heavy enterprise adoption across major cloud platforms including AWS, Google Cloud, and Microsoft Azure.
Moonshot Launches Kimi K2 Thinking: 1T Model Rivals GPT-5
On November 6, 2025, Moonshot AI introduced Kimi K2 Thinking, a 1-trillion-parameter open-weight model designed for complex reasoning and tool use. With a reported 44.9% score on Humanity’s Last Exam and highly competitive inference costs, the model offers a new alternative to proprietary systems like GPT-5 and Claude Sonnet 4.5 for agentic workflows and data analysis.