
Moonshot Launches Kimi K2 Thinking: 1T Model Rivals GPT-5
Image Credit: Jacky Lee
Chinese artificial intelligence company Moonshot AI has introduced Kimi K2 Thinking, an open-weight large language model designed for long-horizon reasoning and multi-step tool use. Released on 6 November 2025, the model expands the existing Kimi K2 series and is described by the company as a general-purpose agent capable of autonomously planning and executing 200 to 300 tool calls within a single workflow.
The release aligns with a broader trend among Chinese AI developers adopting open-weight models as an alternative to proprietary systems from companies including OpenAI, Anthropic and Google. K2 Thinking is built on a mixture-of-experts (MoE) architecture with 1 trillion total parameters, 32 billion of which are active per token. It supports a context window of approximately 256,000 tokens, allowing it to handle large document collections and workflows involving extensive tool usage.






























Company Origins and Strategic Foundations
Moonshot AI was founded in March 2023 in Beijing by Yang Zhilin, Zhou Xinyu and Wu Yuxin. The company is commonly referenced within China’s emerging large-model sector, alongside others such as Baichuan, MiniMax and DeepSeek.
The company’s fundraising history includes several sizable rounds:
Seed and Series A (2023): Approximately US$60 million at a valuation of around US$300 million, with an estimated team size of 40.
February 2024: A US$1 billion round led by Alibaba, valuing the company at roughly US$2.5 billion.
August 2024: A US$300 million round involving Tencent and Gaorong Capital, with a valuation of about US$3.3 billion.
Late 2025: Reports indicate the company is close to completing a new round of approximately US$600 million, led by IDG Capital. A Wall Street Journal–associated report notes that the final valuation could reach about US$4 billion, depending on terms.
Moonshot AI’s chief executive, Yang Zhilin, has a research-focused background that includes studies at Tsinghua University and Carnegie Mellon University, as well as prior roles at Google Brain and Meta AI. His published work includes contributions to models such as Transformer-XL and XLNet, which relate to long-context processing and training efficiency — areas that are reflected in the company’s technical direction.
Moonshot AI’s primary consumer-facing product, the Kimi chatbot, became publicly available in November 2023. The initial version supported context windows of up to 128,000 tokens. In March 2024, the company began beta testing a version capable of processing up to 2 million Chinese characters in a single prompt. This long-context capability contributed to substantial user growth, with the service reaching more than 36 million monthly active users by late 2024.






























From Kimi Foundations to K2 Thinking
The Kimi K2 series forms the basis of Moonshot AI’s current model lineup. K2 is a 1-trillion-parameter mixture-of-experts (MoE) model, trained on approximately 15.5 trillion tokens, with 32 billion parameters active per token. It is distributed as an open-weight model under a modified MIT licence.
Several developments contributed to the progression from the original Kimi models to K2 Thinking:
Kimi K2 Base (July 2025):
Introduced the core 1-trillion-parameter MoE architecture, featuring 32B active parameters per token and support for context windows up to 128,000 tokens. Training employed the Muon / MuonClip optimiser to maintain stability across the roughly 15.5 trillion training tokens.Kimi K2 Instruct-0905 (September 2025):
An instruction-tuned variant that expanded the context window from 128,000 to 256,000 tokens and improved performance on coding-related and agent-oriented tasks.Kimi-Researcher (mid-2025):
A research-focused agent within the Kimi application, designed for multi-document analysis and long-form synthesis. Its capabilities anticipated some of the agentic features later incorporated into K2 Thinking.Kimi K2 Thinking (released 6 November 2025):
Advances this development path by training the model end-to-end as a tool-using agent. According to Moonshot AI’s technical documentation, K2 Thinking is designed to interleave stepwise reasoning with external tool calls, such as code execution or search, and to manage workflows involving 200–300 sequential tool steps without human intervention.
Industry reports, including those citing CNBC, state that the additional training required to convert K2 into K2 Thinking cost about US$4.6 million. This cost level has been attributed to the use of sparse MoE routing and INT4-focused efficiency strategies.




























Architecture, Training and Capabilities
Kimi K2 Thinking maintains the underlying 1-trillion-parameter MoE architecture of K2 but includes adjustments aimed at tasks involving multi-step reasoning and tool coordination.
Sparse Mixture-of-Experts: The model activates 32 billion parameters per token. This reduces inference cost to a level comparable with a dense model of roughly 30–40 billion parameters while retaining the larger MoE capacity.
Long-context processing: A 256,000-token context window enables the model to handle extended input sequences such as large code repositories, multi-document collections, or long chat histories. Context caching within the Kimi platform further supports high-volume inputs.
Muon / MuonClip optimisation: Both K2 and K2 Thinking use the MuonClip optimiser, described by Moonshot AI as providing more stable large-scale training and greater efficiency than AdamW, particularly on long training runs where loss instability is common.
INT4-oriented design: K2 Thinking is trained using quantisation-aware methods to support native INT4 inference. According to Moonshot AI and external assessments, INT4 deployment can increase throughput relative to FP16 on compatible hardware while maintaining competitive output quality.
The overall training approach incorporates a combined reasoning-and-action framework layered on top of large-scale pre-training:
Pre-training: Approximately 15.5 trillion tokens drawn from internet, code, and curated datasets.
Supervised fine-tuning: Demonstrations covering reasoning, coding, and tool-use sequences.
Reinforcement learning: Reward signals applied where results can be automatically verified, such as code execution tests or fact-query checks, reducing dependence on subjective human annotation.
This design supports workflows in which K2 Thinking breaks tasks into multiple intermediate steps, such as reading inputs, forming intermediate conclusions, invoking tools, and updating results, rather than producing a single uninterrupted text output.



























Benchmarks and Comparative Performance
Moonshot AI and various independent evaluators report that Kimi K2 Thinking performs competitively across agentic, reasoning and coding benchmarks, particularly when tool use is enabled. Reported scores differ across evaluators, but several trends appear consistently in published summaries.
Agentic and Reasoning Benchmarks
According to Moonshot AI’s documentation and third-party benchmark aggregators:
Humanity’s Last Exam (HLE, with tools): K2 Thinking reports a score of 44.9%, compared with published results of approximately 41–42% for GPT-5 and lower scores for Claude Sonnet 4.5 in the same tool-enabled configuration.
BrowseComp (agentic web search): K2 Thinking reports 60.2%, with GPT-5 figures generally in the 54–55% range. Some independent comparisons list Claude Sonnet 4.5 in the mid-20% range on this evaluation.
On indices compiled by Artificial Analysis:
Intelligence Index: K2 Thinking is listed with a score of 67, reported as the highest among open-weight models and second to GPT-5 among models evaluated.
Agentic Index: The model is ranked #2 globally, supported in part by a reported 93% result on τ²-Bench Telecom, a customer-support-focused agent benchmark audited by Artificial Analysis.
Coding and Software Engineering
On SWE-Bench Verified, a GitHub-based bug-fixing benchmark, K2 Thinking achieves roughly 71.3% accuracy when tool use is enabled. This places it among the stronger open-weight models reported on this task.
However, benchmark leadership varies by evaluation. Anthropic presents Claude Sonnet 4.5 as achieving state-of-the-art results on SWE-Bench Verified, and several comparisons note that while K2 Thinking performs well relative to open-weight peers, it can trail certain proprietary models depending on the task or test variant.
Mathematics and Exam Benchmarks
K2 Thinking performs strongly on mathematics and competition-style evaluations when paired with tools such as Python:
AIME 2025 (with Python): Reported scores of ~99–99.1%.
HMMT 2025 (with tools): Reported results in the mid-90% range.
GPQA Diamond: Several aggregators list K2 Thinking at approximately 85.7%, with GPT-5 and GPT-5.1 commonly reported in the 84–85% range. The differences are generally within typical benchmark variance.
Given variations in methodology, tool configuration and prompt design across evaluators, most analysts interpret these results as indicating broad performance parity among the top models rather than definitive rankings.






























Pricing, Licensing and Deployment Options
K2 Thinking is positioned as a cost-efficient option within the frontier-model segment, with both API access and open-weight deployment available.
API Pricing
As of November 2025, publicly listed or commonly referenced pricing for Kimi K2 Thinking through major API providers generally falls within the following ranges:
Input tokens: Approximately US$0.45–0.60 per million, depending on the provider and the use of caching.
Output tokens: Approximately US$2.35–2.50 per million.
Moonshot AI’s own documentation for the broader K2 series includes tiered pricing, with cached input tokens sometimes listed as low as US$0.15 per million in specific configurations. Actual costs vary by workload and the extent to which context caching or batching can be used.
For comparison:
OpenAI GPT-5: Around US$1.25 per million input tokens and US$10 per million output tokens.
Anthropic Claude Sonnet 4.5: Around US$3 per million input tokens and US$15 per million output tokens.
These differences indicate that K2 Thinking is priced lower on a per-token basis than several leading proprietary models, particularly for output tokens. However, overall cost depends on factors such as reliability, integration complexity, hardware availability, and operational overhead.
Open-Weight Release and Self-Hosting
K2 Thinking is distributed as an open-weight model and can be downloaded from platforms including Hugging Face, ModelScope and Ollama. The model is released under a modified MIT licence.
The licence includes attribution requirements above certain usage thresholds, for example, commonly cited figures of more than 100 million monthly active users or US$20 million in monthly revenue, while remaining permissive for smaller-scale deployments, experimentation and research.
In deployment:
Full-precision configurations generally require multi-GPU clusters with substantial VRAM capacity due to the size of the MoE architecture when loading many experts simultaneously.
Quantised variants (commonly INT4) are expected to be used in most production environments, along with sharded inference engines such as vLLM or other runtimes capable of handling MoE routing and external-tool invocation.
The availability of both API access and self-hosting provides deployment flexibility, which may be relevant for organisations that favour in-house processing due to regulatory, privacy or infrastructure considerations.



























Comparative Landscape: Open Weights vs Proprietary Models
Within the current generation of large language models, Kimi K2 Thinking occupies a position that reflects both the progress of open-weight systems and the distinctions that remain between open and proprietary approaches.
Relative to GPT-5 / GPT-5.1: On certain agentic benchmarks, such as Humanity’s Last Exam (HLE) and BrowseComp, reported results place K2 Thinking slightly ahead of GPT-5 under similar tool-enabled settings. K2 Thinking reports 44.9% on HLE compared with GPT-5 results generally in the low-40% range, and 60.2% on BrowseComp compared with published GPT-5 figures in the mid-50% range. Differences vary across evaluators and configurations.
Relative to Claude Sonnet 4.5: Comparisons indicate differing strengths. K2 Thinking reports higher results on some search-oriented and long-horizon agentic tasks, while Claude Sonnet 4.5 is presented as stronger on several coding evaluations, including variants of SWE-Bench. Claude also remains competitive in long-context enterprise workflows, depending on use case and tool configuration.
Relative to Other Open-Weight Models: Benchmark aggregators such as Artificial Analysis list K2 Thinking as one of the highest-scoring open-weight models across intelligence and agentic indices. Reported results place it above several large open-weight releases from DeepSeek, MiniMax and Qwen in aggregate measures, though outcomes on specific benchmarks may be closer.
Overall Positioning: These comparisons suggest that open-weight systems such as K2 Thinking can achieve performance levels approaching or equalling proprietary models on some reasoning and agentic tasks. At the same time, proprietary models typically maintain advantages in areas such as multimodal breadth, platform integration, and enterprise tooling.





























Broader Ramifications for AI Ecosystems
The introduction of Kimi K2 Thinking highlights several wider developments in contemporary AI ecosystems.
Open-Weight Models at Higher Capability Levels: Recent releases such as K2 Thinking and DeepSeek V3 indicate that models with advanced reasoning abilities are increasingly available in open-weight form. For organisations with the necessary compute resources, open-weight models enable on-premises deployment, optional fine-tuning and more direct control over data handling — factors that are relevant in regulated sectors including finance, healthcare and government.
Cost and Efficiency Trends: Moonshot AI reports that upgrading K2 to K2 Thinking required approximately US$4.6 million in additional training cost. This figure is substantially lower than the costs associated with earlier frontier-scale models, due in part to sparse MoE routing and INT4-oriented efficiency. Such developments contribute to broader industry discussions about the cost–performance balance of large models and may influence pricing structures across both open and proprietary offerings.
China’s Model Development Strategy: K2 Thinking aligns with ongoing efforts by Chinese AI developers to advance long-context and efficiency-focused architectures, partly in response to constraints on access to high-end GPUs resulting from U.S. export controls. Many Chinese labs have emphasised software optimisation, quantisation and model-parallelism strategies to maximise available compute resources.
Expansion of Agentic AI: K2 Thinking’s design, optimised for multi-step tool use and evaluated on workflows involving 200–300 sequential tool calls, reflects a broader shift toward agentic systems capable of executing extended tasks with minimal human intervention. These systems aim to support activities such as software development, research assistance and operational automation. While anecdotal reports from early adopters describe reduced manual workload for certain tasks, comprehensive productivity assessments are still limited.





















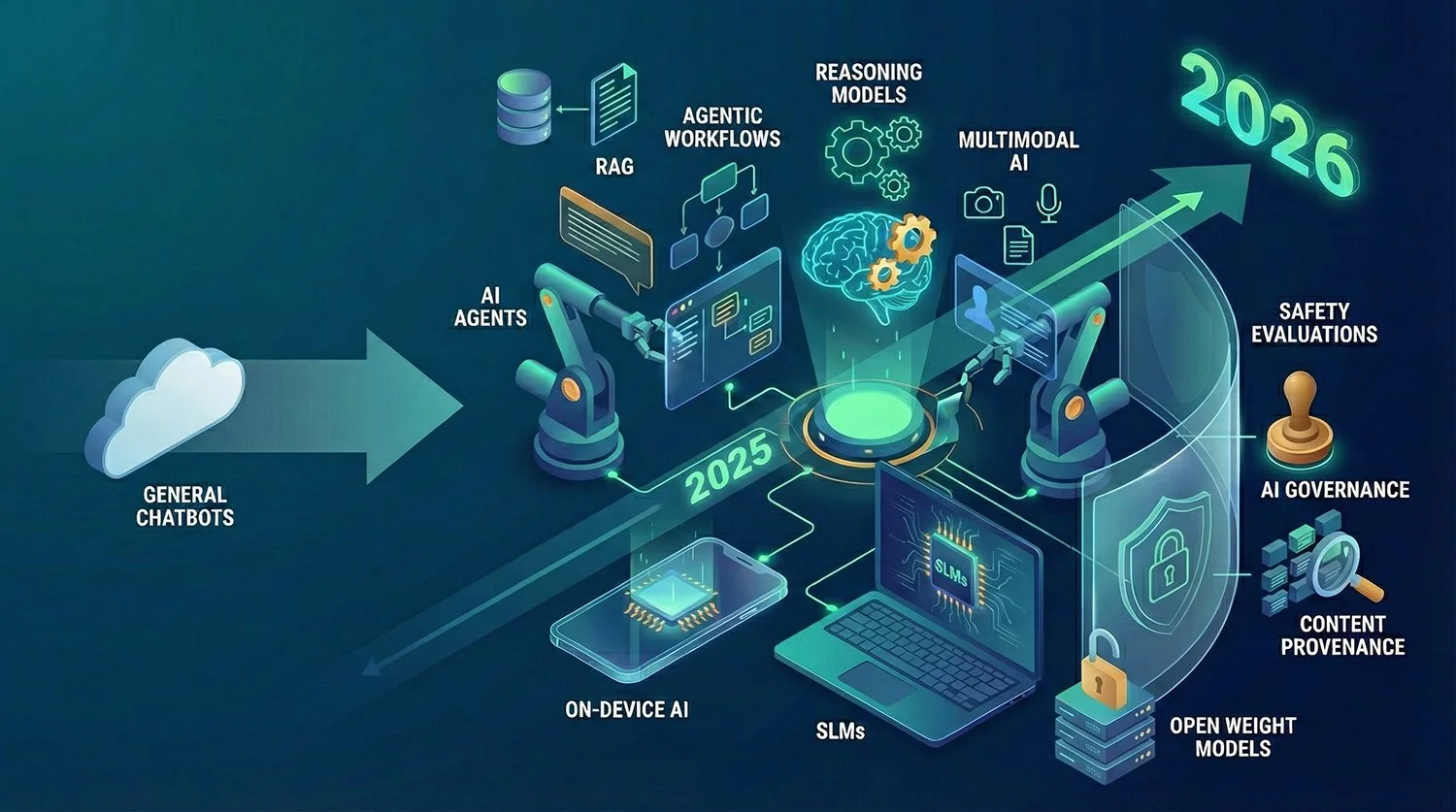
Trajectories Ahead: Agents, Verification and Hybrid Stacks
Kimi K2 Thinking is viewed by many analysts not as a final point in the K2 series, but as an indication of where open-weight frontier models may be moving.
Execution-Focused Training Approaches: K2 Thinking’s use of verifiable outcomes, such as code tests or tool-based checks, as part of its reinforcement learning process reflects a shift toward training methods that prioritise objectively measurable results. This approach is expected to influence the development of future agent-oriented models, particularly in domains such as software engineering, data processing and scientific analysis.
Potential for Multimodal Expansion: Moonshot AI already provides other Kimi variants incorporating vision and audio capabilities. Observers expect future generations, often described informally as “K3-era” systems, to integrate multiple modalities within agentic frameworks, similar to the direction taken by OpenAI, Anthropic and Google in their multimodal model families.
Hybrid Model Ecosystems: As open-weight systems improve, organisations may increasingly combine different model types depending on requirements:
Open-weight deployments (e.g., K2 Thinking) for cost-sensitive, privacy-focused or self-hosted scenarios.
Proprietary APIs (e.g., GPT-5, Claude Sonnet 4.5) for multimodal workloads or applications that depend on vendor-specific integrations and services.
Outlook: K2 Thinking illustrates the level of reasoning and agentic capability that open-weight models can currently achieve under a permissive licence structure. Future adoption levels, and the responses from competing model providers, will influence how significant 2025 becomes in the broader transition toward open-weight agentic systems.






















































We are a leading AI-focused digital news platform, combining AI-generated reporting with human editorial oversight. By aggregating and synthesizing the latest developments in AI — spanning innovation, technology, ethics, policy and business — we deliver timely, accurate and thought-provoking content.