Fei-Fei Li’s New AI Model Redefines Distillation: Challenging DeepSeek at Just US$14?

Fei-Fei Li
Image Source: Stanford University
(The image has been horizontally extended for design presentation purposes.)
Fei-Fei Li, one of the most influential figures in artificial intelligence, has unveiled s1-32B — a reasoning-focused model distilled at a cloud cost well under US$50, with independent estimates suggesting it may be as low as about US$14. Introduced in a January 31, 2025 research paper, the 32-billion-parameter system surpasses OpenAI’s o1-preview in multiple reasoning benchmarks. Yet its closest point of comparison may be DeepSeek’s R1, sibling to the DeepSeek-V3 model whose development was famously linked to a US$5.6 million training budget.
Model s1-32B: Distillation’s New Benchmark
Li, working with researchers from Stanford University and the University of Washington, distilled s1-32B from Alibaba’s open-source Qwen2.5-32B-Instruct model. The team fine-tuned the model using a small, highly curated 1,000-example “s1K” dataset, completing the process in just 26 minutes on 16 Nvidia H100 GPUs via Alibaba Cloud.
In reasoning tasks, s1-32B demonstrates striking performance — beating o1-preview by up to 27% on the 2024 AIME mathematics competition problems. This leap is partly attributed to a “budget forcing” technique, which improves accuracy by prompting the model to extend and refine its reasoning at test time.
The resulting efficiency places s1-32B’s distillation cost orders of magnitude below that of DeepSeek’s training pipeline. While DeepSeek-V3 became known for its comparatively modest US$5.6 million budget, s1-32B showcases what ultra-lean distillation can achieve when paired with a targeted dataset and lightweight test-time scaling.
DeepSeek’s R1, released in late January 2025 and quickly reaching the top of U.S. App Store rankings, remains positioned as a wide-scope chatbot. In contrast, s1-32B’s narrow reasoning focus highlights a fundamentally different — and far cheaper — path to model capability.
On paper, s1-32B is hundreds of thousands of times cheaper to produce than DeepSeek-V3. Though the comparison is illustrative rather than direct, it underscores how aggressively cost-efficient modern distillation can become.
Cost Estimates: A Clarified Range
Reporting on s1-32B’s cloud compute cost varies:
PanewsLab and The Verge both cite the total cost as under US$50.
Tim Kellogg estimated an ultra-low cost of ~US$6, though this does not align well with typical market pricing.
Using early-2025 rental averages from providers such as Hyperstack, CUDO Compute, RunPod, and Nebius — roughly US$2 per H100 per hour — a 26-minute run on 16 GPUs yields an estimated cost around US$14.
This calculated estimate aligns with ranges referenced by outlets such as The Economic Times, making “under US$50” the confirmed figure, with US$14 a plausible independent estimate based on realistic GPU pricing.
[Read More: Can a US$5.6 Million Budget Build a ChatGPT-Level AI? ChatGPT o3-mini-high Says No!]
Fei-Fei Li: A Visionary’s Journey
Fei-Fei Li, honored with the 2025 Queen Elizabeth Prize for Engineering alongside her ImageNet collaborators, continues to influence the trajectory of global AI research.
Born in Beijing in 1976, Li migrated to the United States at age 15. After working in a Chinese restaurant during high school, she graduated with a physics degree from Princeton University in 1999 and completed a Ph.D. in electrical engineering at Caltech in 2005. In 2009, she co-created ImageNet, a dataset that revolutionized computer vision and catalyzed the deep-learning era.
Li now serves as a professor at Stanford and co-founded World Labs, a startup developing AI that understands the physical world. Her memoir, The Worlds I See, reflects her human-centered AI philosophy and immigrant journey.
[Read More: DeepSeek AI Faces Security and Privacy Backlash Amid OpenAI Data Theft Allegations]
Qwen’s Role: Open vs. Elite
s1-32B is built upon Qwen2.5-32B-Instruct, Alibaba’s openly released 32-billion-parameter model launched in September 2024 and trained on a corpus exceeding 5.5 trillion tokens. The model is strong in both programming and mathematics, scoring 84.0 on MBPP and 83.1 on the MATH benchmark.
DeepSeek’s R1 also incorporates distillation into its development workflow, though the company has not disclosed the exact source models used for its teacher signals. Public documentation confirms the use of distillation techniques but not the identity of any proprietary models.
[Read More: DeepSeek’s 10x AI Efficiency: What’s the Real Story?]
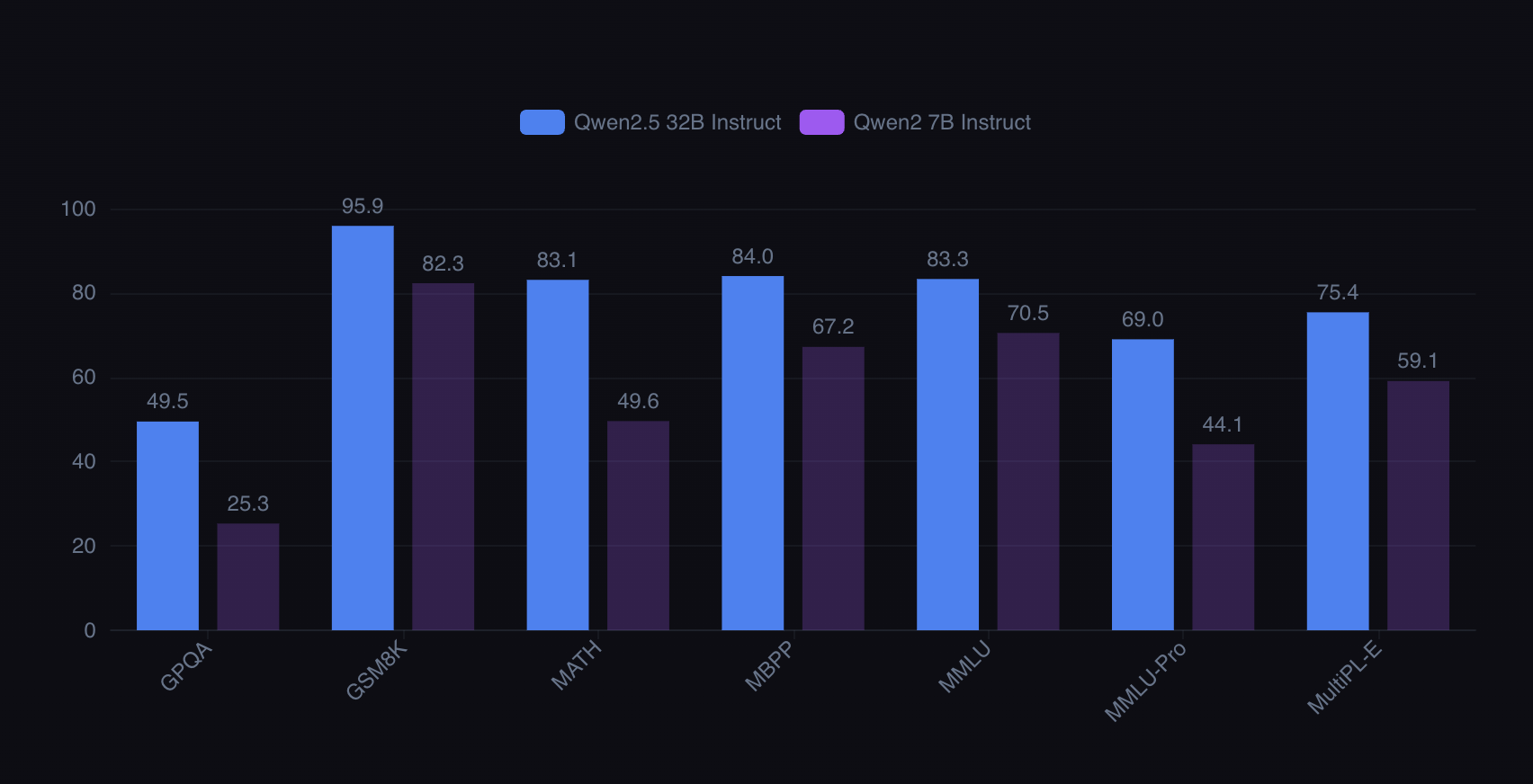
Image Source: LLM Stat
Around the same time, Alibaba also introduced Qwen2.5-Max, a Mixture-of-Experts system launched on January 29, 2025. Trained on over 20 trillion tokens and scoring 89.4 on the Arena-Hard leaderboard, Qwen2.5-Max is accessible only via API, contrasted sharply with the fully open-weight Qwen2.5-32B-Instruct that underpins Li’s work. However, neither Li’s team nor DeepSeek have publicly indicated using Qwen2.5-Max as a distillation teacher; their advances are driven primarily by open-weight models and proprietary thinking-mode teachers.
Meanwhile, OpenAI and U.S. authorities are investigating whether DeepSeek may have used OpenAI outputs in ways that violate API usage terms. No concrete findings have been disclosed as of February 24, 2025.
[Read More: Why Did China Ban Western AI Chatbots? The Rise of Its Own AI Models]
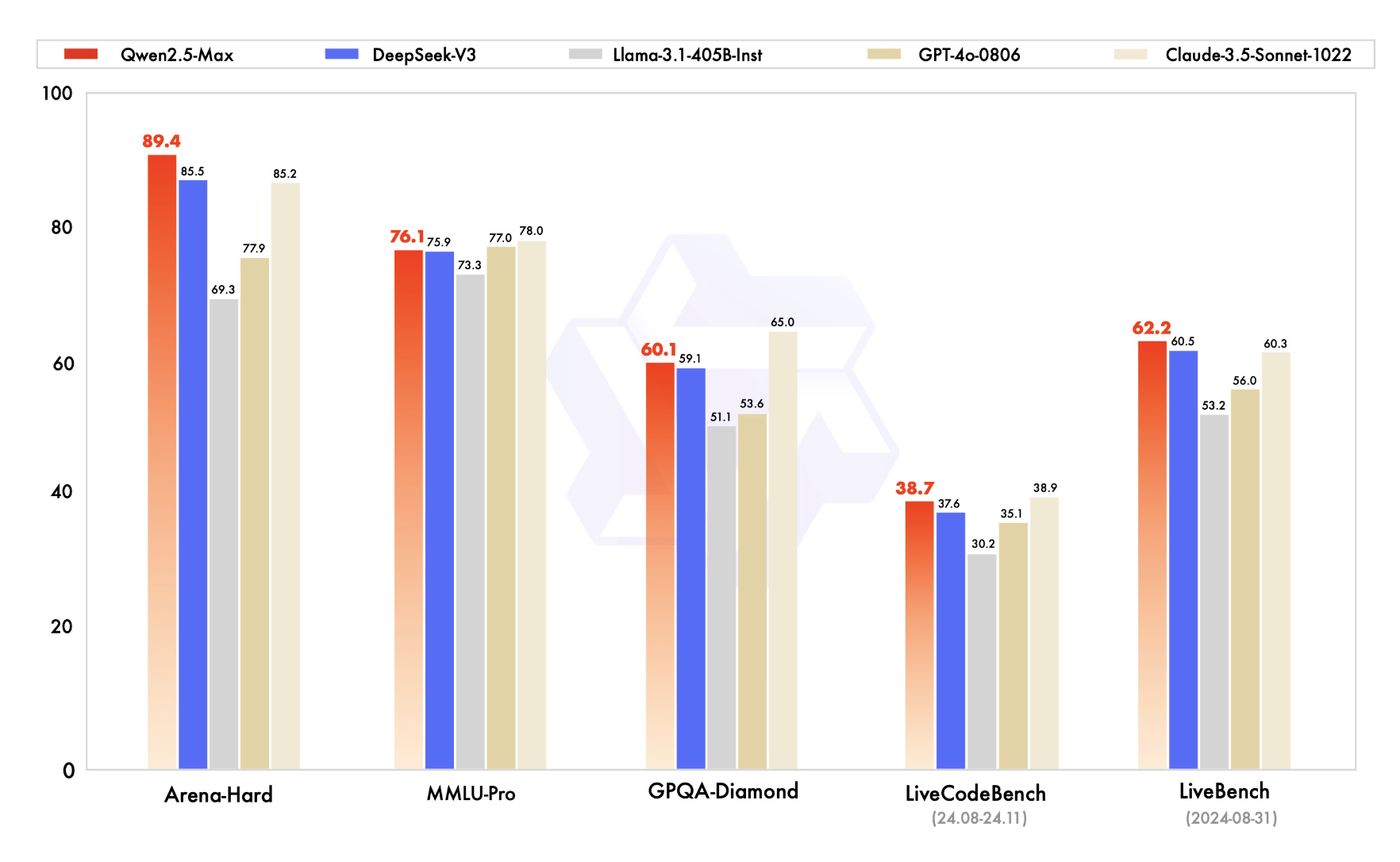
Image Source: QwenLM GitHub
Industry Stakes: A Cost-Efficiency Race
The release of DeepSeek’s R1 in January 2025 triggered a dramatic market response, coinciding with a US$1 trillion selloff in global tech stocks. Nvidia alone lost nearly US$600 billion in market capitalization on January 27, 2025, reflecting fears that ultra-low-cost Chinese model development may reshape the economics of AI.
Fei-Fei Li’s s1-32B offers a different lens on cost reduction — one rooted not in massive proprietary training runs but in small, curated datasets, open-source foundations, and clever test-time scaling.
While public debate continues over whether DeepSeek may have relied on proprietary model outputs, no verified evidence has emerged. In contrast, Li’s team built s1-32B entirely on publicly documented components, avoiding similar scrutiny.
As the industry weighs the true cost of artificial intelligence — in compute, data, transparency, and ethics — s1-32B stands as a fresh demonstration that breakthroughs need not always require billion-dollar budgets.
[Read More: Apple-Alibaba AI Alliance: Boosting Revenue or a Privacy Concern?]
Source: Stanford University, QE Prize, arXiv, AP News, The Wall Street Journal, Princeton Alumni, Reuters, Qwen, Hugging Face, CCN