
AI Stock Forecasts: Perplexity and Grok Top Broadcom Prediction Study

Disclaimer: This article is for informational and educational purposes only. The predictions and analyses presented herein were generated by AI systems and should not be construed as financial advice, investment recommendations, or solicitations to buy or sell any securities. Stock prices are inherently unpredictable, and all investments carry risk of loss. Past performance does not guarantee future results. Readers should consult qualified financial advisors before making any investment decisions. TheDayAfterAI News and its contributors do not accept liability for any losses arising from reliance on this content.
Last month, TheDayAfterAI News asked five leading AI chatbots — Perplexity, Google Gemini, xAI's Grok, OpenAI's ChatGPT, and Anthropic's Claude — to predict Broadcom Inc. (NASDAQ: AVGO) stock performance for the trading week of December 16–22, 2025. The predictions came at a critical moment: Broadcom had just reported stellar Q4 FY2025 earnings that nonetheless triggered a sharp 16-17% selloff from its all-time high of $414.61, leaving the stock technically oversold but sentiment mixed.
What made this experiment particularly compelling was the unanimous bullish consensus: all five AI models predicted a greater-than-50% probability of recovery, with forecasts ranging from ChatGPT's conservative 54% to Gemini's optimistic 65%. Now that the week has concluded, we evaluate each AI's accuracy across five distinct categories: trend direction, opening price, closing price, weekly low, and weekly high.




























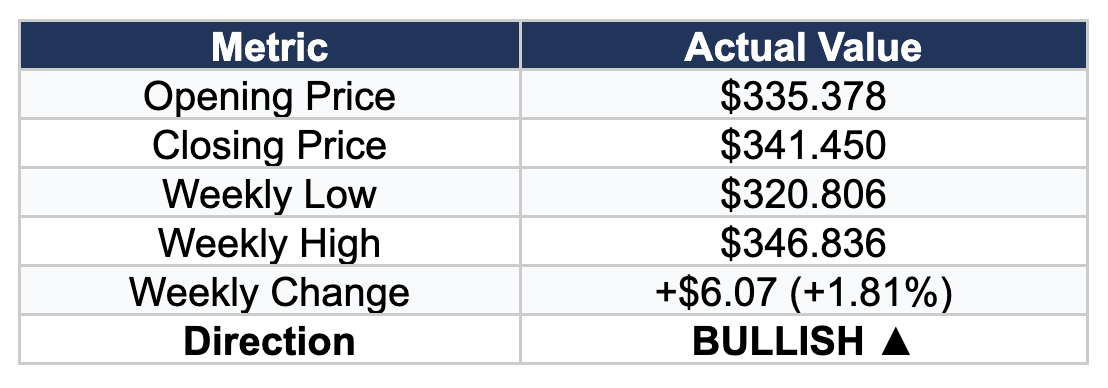
Actual AVGO Performance: December 16–22, 2025
Broadcom delivered the recovery that all five AIs anticipated, though the magnitude was more modest than most predicted. The stock opened at $335.38, dipped to a weekly low of $320.81 mid-week, then rallied to close at $341.45 — a gain of 1.81% from the open.






























Category-by-Category Rankings
We evaluated each AI across five categories, using percentage error from actual values. Lower percentage = better accuracy. Points awarded: 1st place = 5 pts, 2nd = 4 pts, 3rd = 3 pts, 4th = 2 pts, 5th = 1 pt.






























Category 1: Best Trend/Direction Prediction
Actual Result: BULLISH (+1.81% weekly gain)
Winner: Gemini — Highest confidence (65%) on the correct bullish call.
In a remarkable display of consensus, all five AI models correctly predicted Broadcom would finish the week higher. Since all predictions were correct, we ranked by confidence level — the AI that was most certain about the correct direction earned the most points.





























Category 2: Best Opening Price Prediction
Actual Opening Price: $335.378
Winner: Perplexity — Just 0.19% off the actual opening price with its $336 prediction.






























Category 3: Best Closing Price Prediction
Actual Closing Price: $341.450
Winner: ChatGPT — Most conservative estimate of $347 came closest to the actual $341.45.
This category revealed a critical insight: all five AIs overestimated Broadcom's recovery. While they correctly predicted the direction, they were uniformly too optimistic about the magnitude. ChatGPT's conservative stance — the lowest closing price prediction at $347 — proved most accurate.































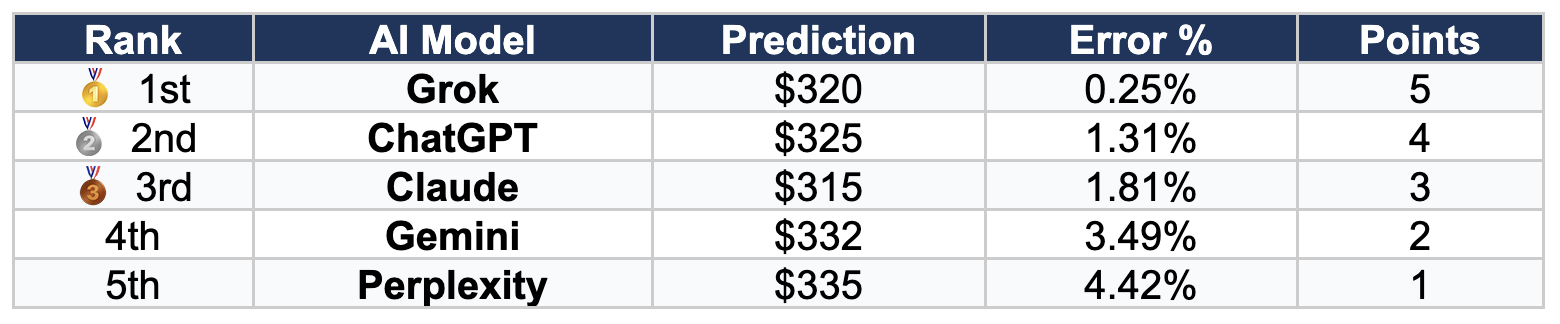
Category 4: Best Weekly Low Prediction
Actual Weekly Low: $320.806
Winner: Grok — Predicted the floor at $320, just 0.25% off the actual low — the best single prediction in the experiment!
Grok's floor prediction of $320 (from its $320-$370 range) came within pennies of the actual weekly low of $320.81. This remarkable accuracy demonstrates Grok's strength in technical support level analysis.




























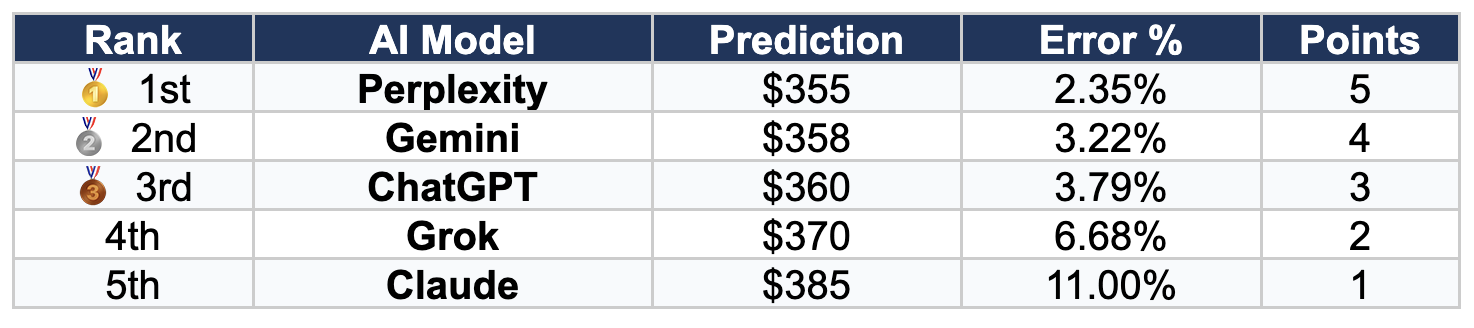
Category 5: Best Weekly High Prediction
Actual Weekly High: $346.836
Winner: Perplexity — Predicted the ceiling at $355, just 2.35% off the actual high.
Perplexity's tighter trading range ($335-$355) proved most accurate for the weekly high. Claude's widest range ($315-$385) resulted in the largest error at 11%, highlighting how overly broad predictions can miss the mark on specific price targets.





























Final Overall Rankings
Based on total points earned across all five categories:




























Category Winners at a Glance
🎯 Best Trend Prediction: Gemini (65% bullish confidence — highest and correct)
📈 Best Opening Price: Perplexity (0.19% error)
📉 Best Closing Price: ChatGPT (1.62% error)
⬇️ Best Weekly Low: Grok (0.25% error — best single prediction!)
⬆️ Best Weekly High: Perplexity (2.35% error)


























Key Takeaways
Why Perplexity Won Overall: Perplexity's victory came from exceptional balance rather than category dominance. While it won two categories outright (Opening Price and Weekly High), its consistent top-half finishes across all categories accumulated 18 points. Perplexity's citation-heavy, real-time data approach produced the tightest overall predictions, suggesting that access to current market data significantly improves forecast accuracy.
Grok's Remarkable Floor Call: Grok produced the single most accurate prediction in the entire experiment: a weekly low forecast of $320 that came within 0.25% of the actual $320.81. This continues Grok's pattern from previous experiments of exceptional technical support/resistance analysis. Grok's detailed examination of sector dynamics and global market influences helped it identify key price levels with unusual precision.
The ChatGPT Paradox: ChatGPT presents an interesting paradox: despite having the lowest confidence in its bullish call (54%), it produced the most accurate closing price prediction. This suggests that ChatGPT's conservative approach — which cost it points in the trend category — actually benefited its price target accuracy. Sometimes being less confident can lead to more realistic estimates.
Claude's Wide Range Problem: Claude's widest trading range ($315-$385) proved both a strength and weakness. While its $315 floor was reasonably close to the actual low, its $385 ceiling was 11% above the actual high — the largest error in any single category. Claude's comprehensive risk-aware framework excels at identifying worst-case scenarios but struggles with precise upside targets. Its overestimation of the closing price ($362.50 vs $341.45) suggests excessive bullish expectations despite its moderate 55% confidence.
The Universal Overestimation: Perhaps the most striking finding is that all five AIs overestimated Broadcom's recovery. While they correctly identified the direction, their closing price predictions ranged from $347 to $362.50 — all above the actual $341.45. This systematic bias suggests that AI models may overweight oversold technical indicators when predicting mean reversion magnitude.
Reliability Assessment: What We've Learned
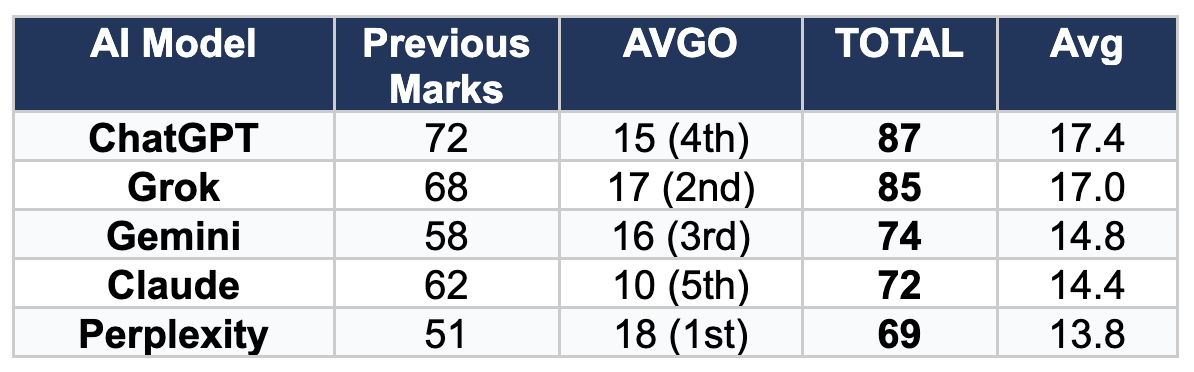
Most Reliable Overall: ChatGPT (OpenAI)
With 87 cumulative points across five rounds, ChatGPT maintains its position as the most dependable AI for stock prediction. Its two first-place finishes (IRBT and ORCL) combined with no finishes below 4th place demonstrate an analytical framework that adapts well to different market conditions. ChatGPT's strength lies in balanced, conservative predictions that avoid extreme positions.
Best for Technical Analysis: Grok (xAI)
Grok's consistent runner-up finishes (TSLA 1st, ORCL 2nd, AVGO 2nd) and exceptional support/resistance accuracy make it the go-to choice for technical price level predictions. Its 0.25% error on Broadcom's weekly low exemplifies this strength. When precise entry/exit points matter more than directional confidence, Grok delivers.
Most Improved: Perplexity (Perplexity AI)
Perplexity's trajectory from 5th place (IRBT) to 1st place (AVGO) represents the most dramatic improvement in our testing. Its real-time data access and citation-heavy methodology appear to be maturing rapidly. If this trend continues, Perplexity could challenge ChatGPT and Grok for overall leadership.
Highest Variance: Claude (Anthropic)
Claude shows the widest performance variance — ranging from 1st place (NVDA) to 5th place (TSLA, ORCL, AVGO). Its risk-aware framework excels when market conditions align with its conservative methodology but struggles during strong recovery rallies. Claude remains valuable for identifying downside risks and worst-case scenarios, but investors should be cautious about its upside targets.
Conclusion
The Broadcom experiment reinforced several key lessons from our ongoing AI prediction series. Perplexity's victory with 18 points demonstrates that real-time data access and balanced predictions can outperform both high-confidence directional calls (Gemini) and conservative hedging (ChatGPT).
Most notably, the unanimous bullish consensus from all five AIs proved correct — a rare display of agreement that validated the technical oversold thesis. However, the universal overestimation of recovery magnitude (all closing predictions exceeded actual) reveals a systematic bias that investors should factor into AI-assisted analysis.
For investors considering AI-assisted analysis, the key insight remains consistent: ensemble approaches — consulting multiple AIs and synthesizing their views—produce better results than relying on any single chatbot. Different AIs continue to excel in different areas, and their collective wisdom often outperforms individual predictions.
TheDayAfterAI News will continue this experiment series with additional stocks to build a comprehensive reliability profile for each chatbot across diverse market conditions and asset types.
License This Article
We are a leading AI-focused digital news platform, combining AI-generated reporting with human editorial oversight. By aggregating and synthesizing the latest developments in AI — spanning innovation, technology, ethics, policy and business — we deliver timely, accurate and thought-provoking content.